Even with a cursory introduction to “Big Data”, you will likely see some mention of MapReduce. It provides the framework to Hadoop which in turn has been used (with some modifications) by many applications such as Facebook, Google, Twitter, and Yahoo. MapReduce is a programming model that actually abstracts the complexities of parallel computing and allows users to tap into the power without having to get into the low level architecture. I covered this in my Data Science class and was surprised at how easy it was to pick up. So I copied what they did in Python and created a MapReduce emulator in R.
I won’t get into too much detail on how MapReduce works as there’s plenty of sources online. But, I sketched up a quick diagram so it would be apparent where the advantage comes in.
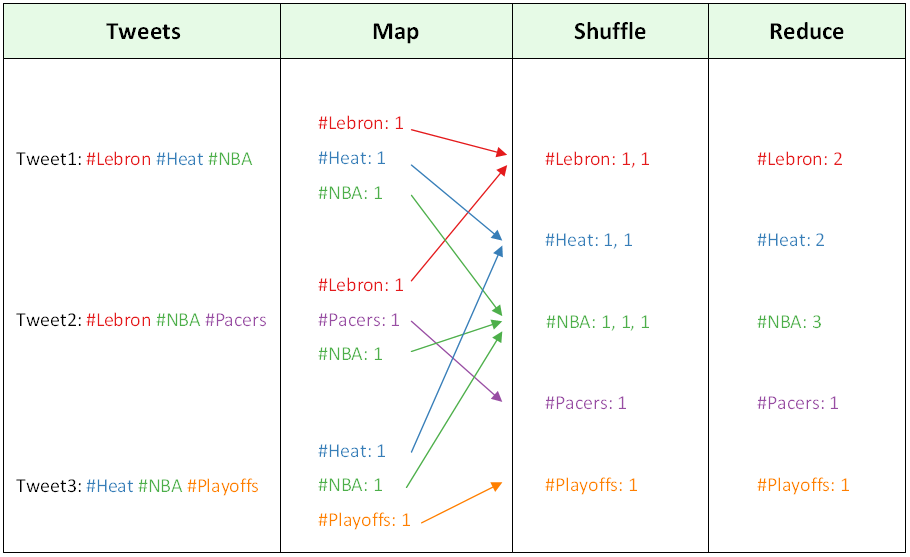
In the image above, I have 3 hypothetical tweets with some hashtags. I want to count the number of times each hashtag shows up. In a standard, non-distributed way I can simply go though each tweet and store a dictionary to count the hashtags. There are 9 hashtags so we would expect one processor to go through 9 operations. More generally, the computation would be O(n).
If we use MapReduce, the goal is to lower the bound to O(n/k) where k is the number of systems we can spread the task on. It’s trivial to see that breaking the work up into chunks would be the solution. MapReduce allows the programmer to do that while only having to worry about two functions, map and reduce. The programmer doesn’t have to care about how to actually write the code to run on parallel processes!
The map function here takes in a tweet and for each hashtag emits the a key value pair: (hashtag, 1). The shuffle happens in the background to group keys together. The reduce function then takes each key value pair of hashtag and list of 1’s, and sums up to produce a full count. The parallelism comes in because the map and reduce functions can be performed on different machines simultaneously. Furthermore, they can be duplicated to provide a level of fault tolerance. Let’s suppose we have 3 machines to do the above. Each one handles a tweet. There is still a total of 9 operations but 3 per machine. The same occurs in the reduce phase. So, the overall problem would run much quicker.
The R code below can be used to simulate MapReduce. Notice, it doesn’t actually run a parallel process but instead allows the user to test their MapReduce code is functional. I was not used to OOP in R, but found this useful example. Below, I have run it on the classic word count among multiple documents problem.
# 1. Run MapReduce Object Constructor
MapReduce mr = list(
intermediate = list(),
result = list()
)
mr$emitIntermediate = function(key, value) {
tp = mr$intermediate
tp[[key]] = c(tp[[key]], value)
assign("intermediate", tp, envir=mr)
}
mr$emitResult = function(key, value) {
tp = mr$result
tp[[key]] = c(tp[[key]], value)
assign("result", tp, envir=mr)
}
mr = list2env(mr)
class(mr) = "MapReduce"
return(mr)
}
# 2. Enter path of input json file
jsonInput = "/data/books2.json"
# 3. Write Map function
map = function(record) {
key = record[1]
value = record[2]
words = strsplit(value, split=" +")
for (w in words[[1]]) {
MR$emitIntermediate(w, 1)
}
}
# 4. Write reduce function
reduce = function(key, list_of_values) {
total = 0
for (v in list_of_values) {
total = total + v
}
MR$emitResult(key, total)
}
# 5. Run code from here
MR = MapReduce()
data = fromJSON (jsonInput)
for (i in 1:length(data)) {
record = data[[i]]
map(record)
}
for (key in names(MR$intermediate)) {
reduce(key, MR$intermediate[[key]])
}
# 6. Output
MR$result
The code will take a bunch of documents and output a full word count of all words among all documents. However, this can be used on any type of data that lends itself to the MapReduce paradigm. It needs an input JSON file. I used a file with rows of [“TITLE”, “TEXT”]. Then the user can write their own map and reduce functions and run code from line 45. Another common problem with the same data set is to create an inverted index, so feel free to gave that a try by changing the above map and reduce functions. Also a simple Google search can provide other problems to test out.